So, what exactly is a cloud-based web scraper? At its core, it's a tool that runs on cloud servers—not your personal computer—to pull data from websites. This simple change in location offers a massive leap in scale and reliability, moving the entire data extraction process into a distributed environment and sidestepping many of the classic headaches of web scraping.
Moving Data Scraping from Your PC to the Cloud

Think about trying to map an entire country with a single car. You’d constantly worry about fuel, traffic, and breakdowns. It would be slow, frustrating, and incredibly inefficient. That's pretty much what it feels like to scrape websites from your personal computer.
Now, imagine a fleet of drones mapping that same country from above, all at once. That's the power of a cloud-based web scraper. It's a fundamental shift from running a small script locally to deploying a large-scale, distributed system for data extraction. While a script on your laptop is fine for a few pages, it just can't keep up with modern business demands.
The Limits of Local Scraping
Kicking off a web scraping project on your own machine is a great way to start, but you’ll hit a wall pretty quickly as your data needs grow. The whole process tends to be fragile and needs a lot of hand-holding.
These are the common pain points that eventually push everyone toward the cloud:
- IP Bans and Blocks: When a website sees hundreds of requests coming from a single IP address, it's a huge red flag. They can easily detect and block your local IP, bringing your data collection to a screeching halt. For example, trying to scrape 1,000 product pages from a major e-commerce site from your home IP address will likely get you blocked within the first 50 requests.
- Resource Constraints: Your computer only has so much memory, CPU power, and bandwidth. Trying to scrape millions of pages will either slow your machine to a crawl or crash your script altogether. A practical example is a script that needs to parse large, complex pages; it might consume several gigabytes of RAM, making it impossible to run alongside your other applications.
- Constant Maintenance: Websites are always changing. A local script means you're constantly updating code, managing dependencies, and fixing things as they break. It turns data collection into a full-time job. For instance, a retailer might change their product page layout, causing your scraper to fail until you manually rewrite the code to find the new price element.
A local scraper is like a solo musician trying to perform a symphony. You might be able to play one part perfectly, but you can never replicate the sound of a full orchestra. A cloud-based web scraper is that orchestra, with every server playing its part in perfect harmony.
Why the Cloud Is the Answer
Moving to the cloud isn't just about making life easier; it's about achieving a level of reliability and scale that's flat-out impossible on a single machine. Take an e-commerce business trying to monitor thousands of competitor prices every day. A local scraper would be completely overwhelmed and likely get blocked after checking just a handful of products.
A cloud solution, on the other hand, distributes these requests across hundreds of different servers, each with its own IP address. This makes the scraping activity look like normal user traffic, effectively sidestepping IP bans and ensuring you get a continuous flow of data. For example, instead of one IP making 10,000 requests, 1,000 different IPs each make just 10 requests, a pattern that is indistinguishable from legitimate customer activity.
By offloading the heavy lifting to specialized infrastructure, businesses can gather information at a global scale, reliably. It transforms data collection from a frustrating chore into a true strategic asset.
How a Cloud Based Web Scraper Actually Works

A cloud based web scraper isn't a single piece of software running on one machine. It’s more like a global intelligence network, a distributed system designed to gather data at a massive scale without getting caught. This architecture is its secret sauce, providing the power and resilience that a local scraper just can't match.
Think of yourself as the director of an operation. You use a central dashboard to define your target and specify exactly what intel you need. Once you hit 'go', the system doesn't just send out one agent; it deploys an entire fleet.
The Command Center and The Field Agents
At the core of any cloud scraping operation is the "command center." This is where you configure your scraping jobs, set schedules, and tell the system where to deliver the final, structured data. The beauty of it is that you never have to touch a server or worry about infrastructure—you just issue the commands.
Your instructions are then broadcast to a network of 'worker' servers. These are your field agents, scattered across data centers all over the world. Each worker is given a small part of the mission and gets to work independently.
The entire strategy is built on "divide and conquer." Instead of one computer trying to hammer a website with 10,000 requests, a cloud scraper might have 1,000 servers each make just 10 requests. To the target website, this looks like normal user traffic, not a brute-force attack.
This distributed approach is what makes large-scale data extraction possible. The global demand for this is exploding, with the web scraping software market valued at USD 501.9 million in 2025 and projected to reach USD 2,030.4 million by 2035. This growth shows just how vital these scalable solutions have become for businesses needing to make sense of the web's massive data pools.
Before we dive deeper, let's break down the fundamental differences between running a scraper on your own machine versus using a cloud-based service.
Local Scraper vs Cloud Based Web Scraper
| Feature | Local Scraper | Cloud Based Web Scraper |
|---|---|---|
| Infrastructure | Runs on your personal computer or server | Hosted on a provider's distributed cloud network |
| Scalability | Limited by your machine's resources | Nearly infinite; scales on-demand |
| IP Management | Single IP address; easily blocked | Manages a vast pool of rotating proxy IPs |
| Maintenance | Your responsibility (updates, fixes, uptime) | Managed entirely by the service provider |
| Reliability | Prone to downtime and network issues | High availability with built-in redundancy |
| Cost | Low initial cost, but high time investment | Subscription-based; predictable operating expense |
As you can see, while a local scraper is fine for small, one-off tasks, a cloud-based approach is built for the serious, ongoing data operations that businesses rely on.
Staying Hidden with Smart Proxies
One of the biggest hurdles in web scraping is simply not getting caught. Websites are smart; if they see a flood of requests from one IP address, they'll shut it down in a heartbeat. This is where the field agents' "disguises" come in: automated proxy management.
Each worker server routes its requests through a different IP address, a technique called proxy rotation. This makes it look like the requests are coming from thousands of individual users from all over the globe. A good cloud based web scraper handles all of this for you, automatically.
Here’s a simplified look at the process:
- Job Distribution: The command center splits the main task into thousands of tiny micro-tasks.
- Proxy Allocation: Each micro-task is assigned to a worker node with a fresh, unique IP address.
- Data Collection: The worker executes the request, grabs the HTML, and sends it back to base.
- Data Aggregation: The command center collects the raw data from all workers and pieces it together into a structured format.
This cycle runs constantly and is incredibly resilient. If one worker server fails or its IP gets blocked, another one instantly takes its place. This ensures your data pipeline never breaks. This kind of hands-off reliability is a game-changer, especially for complex workflows that require more than just simple data fetching. To see how this applies to more advanced tasks, you can learn more about how browser automation works on a server.
A Practical Example in Action
Let’s say a large travel company needs to monitor thousands of flight prices across dozens of airline websites in real-time. Trying to do this from a single office computer is a non-starter. Their IP address would be blacklisted before they even finished their morning coffee.
Instead, they use a cloud based web scraper. They set up a job that runs 24/7, distributing the task across a global network. A server in Germany checks flights from Frankfurt, another in New York checks JFK, and so on. Each request uses a different IP, perfectly mimicking genuine customer searches.
The scraped prices are instantly collected, cleaned up, structured, and fed directly into the company's own pricing database. This allows them to adjust their own flight deals on the fly, staying competitive in a fast-moving market.
The Real-World Benefits of Cloud Scraping

Moving to a cloud based web scraper isn't just a small tech upgrade; it's a strategic jump that brings real, measurable advantages to your business. Sure, a local script might work for a small project, but it just can't compete with the raw power and resilience of a cloud-native solution when things get serious.
The real magic is how these systems solve the most frustrating problems in data extraction. We're talking about everything from getting past IP blocks to making sure your data pipeline never sleeps. Let’s break down the tangible benefits that make cloud scraping an essential tool for any data-driven company.
Achieve Massive and Effortless Scalability
Imagine your data needs explode overnight, going from a few thousand pages to a few million. With a local setup, that’s a nightmare. You’d be scrambling for more powerful hardware and constantly hitting resource limits.
With a cloud scraper, scaling is almost a non-issue.
You can crank up your scraping operations on a dime without ever worrying about server capacity, memory, or bandwidth. A cloud based web scraper is built on a distributed network, meaning it just pulls more resources from its massive pool to handle bigger jobs. This elasticity is a game-changer.
Practical Example: An e-commerce aggregator needs to track prices and stock levels across 5,000 retail sites every single day. Using a cloud scraper, they schedule this huge task to run overnight, spreading the work across hundreds of servers. Every morning, a complete, fresh dataset is ready for their team—something that would be flat-out impossible on a single machine.
Guarantee Uninterrupted Data Flow with High Reliability
Let's be honest: local scrapers are fragile. Your internet connection drops, your computer crashes, or a random software bug appears, and your entire operation grinds to a halt. You're left with frustrating gaps in your data.
Cloud services are built for exactly the opposite scenario. They are designed from the ground up for high availability and redundancy.
These platforms run on rock-solid infrastructure with built-in fail-safes. If one server has an issue, another one instantly picks up the slack. Your jobs keep running 24/7, no interruptions. This means you get a consistent, dependable flow of data, which is absolutely critical for any time-sensitive work. A practical example is a financial firm scraping stock market news; a 10-minute outage on a local scraper could mean missing a critical, market-moving announcement. With a cloud scraper, redundant servers ensure that never happens.
The market's explosive growth reflects this demand. The web scraping market was pegged at USD 1.03 billion by 2025, with some estimates showing it could nearly double by 2030. With about 65% of global enterprises now using data extraction tools, the need for reliable, cloud-based solutions has never been clearer. You can dig into more of these web crawling industry benchmarks on thunderbit.com.
Evade Blocks with Integrated Anonymity
One of the biggest headaches in web scraping is getting blocked. A tidal wave of requests from a single IP address is a massive red flag, and websites will shut you down in a heartbeat.
A cloud based web scraper neatly solves this by using a huge, rotating pool of proxy IP addresses.
Instead of all your requests coming from one place, they're routed through thousands of different IPs all over the world. To the target website, your scraper’s activity looks just like normal traffic from tons of different users. It drastically cuts your chances of being detected and blocked. The best part? It's all automated. You don't have to touch or manage a single proxy yourself.
Here’s why this is so powerful:
- Geographic Targeting: You can make requests look like they're coming from specific countries to access geo-restricted content. For example, a marketing agency can check ad placements in Japan by routing requests through Japanese proxies.
- Automatic Rotation: The system is constantly cycling through IPs to keep websites from getting suspicious.
- Vast IP Pools: You get access to thousands, sometimes millions, of datacenter and residential IPs for top-tier anonymity.
Drastically Reduce Your Maintenance Burden
Running a local scraper is a full-time job. You're on the hook for everything: updating software, managing dependencies, monitoring for downtime, and scrambling to fix your code every time a target site changes its layout. All that maintenance pulls you away from the whole point of the exercise—analyzing the data.
A cloud based web scraper takes all of that off your plate.
The service provider handles the infrastructure, the updates, and all the operational headaches. Your team just has to define what data they need, and the platform does the rest. This frees them up to focus on finding insights that actually drive business value. For instance, if a target website adds a new security measure, the cloud provider's engineering team will adapt the platform to handle it, saving your team days of troubleshooting.
Anatomy of a Cloud Scraping Job
To really get what makes a cloud based web scraper so powerful, let's walk through a single data extraction job—from the moment it’s created to when the clean data lands in your hands. This look behind the curtain breaks down the technical process, showing how a simple request balloons into a massive, automated operation. The whole workflow is built for efficiency and toughness, handling the kind of complexity that would crush a local script in minutes.
Let’s say you’re building a price comparison site for high-end electronics. You need to pull product specs, prices, and stock levels from dozens of major online retailers every single day. Doing this by hand is out of the question, and a script running on your own computer would get blocked almost instantly. This is the perfect mission for a cloud scraper.
The infographic below gives you a bird's-eye view of the process, from your initial input to the final, structured data.
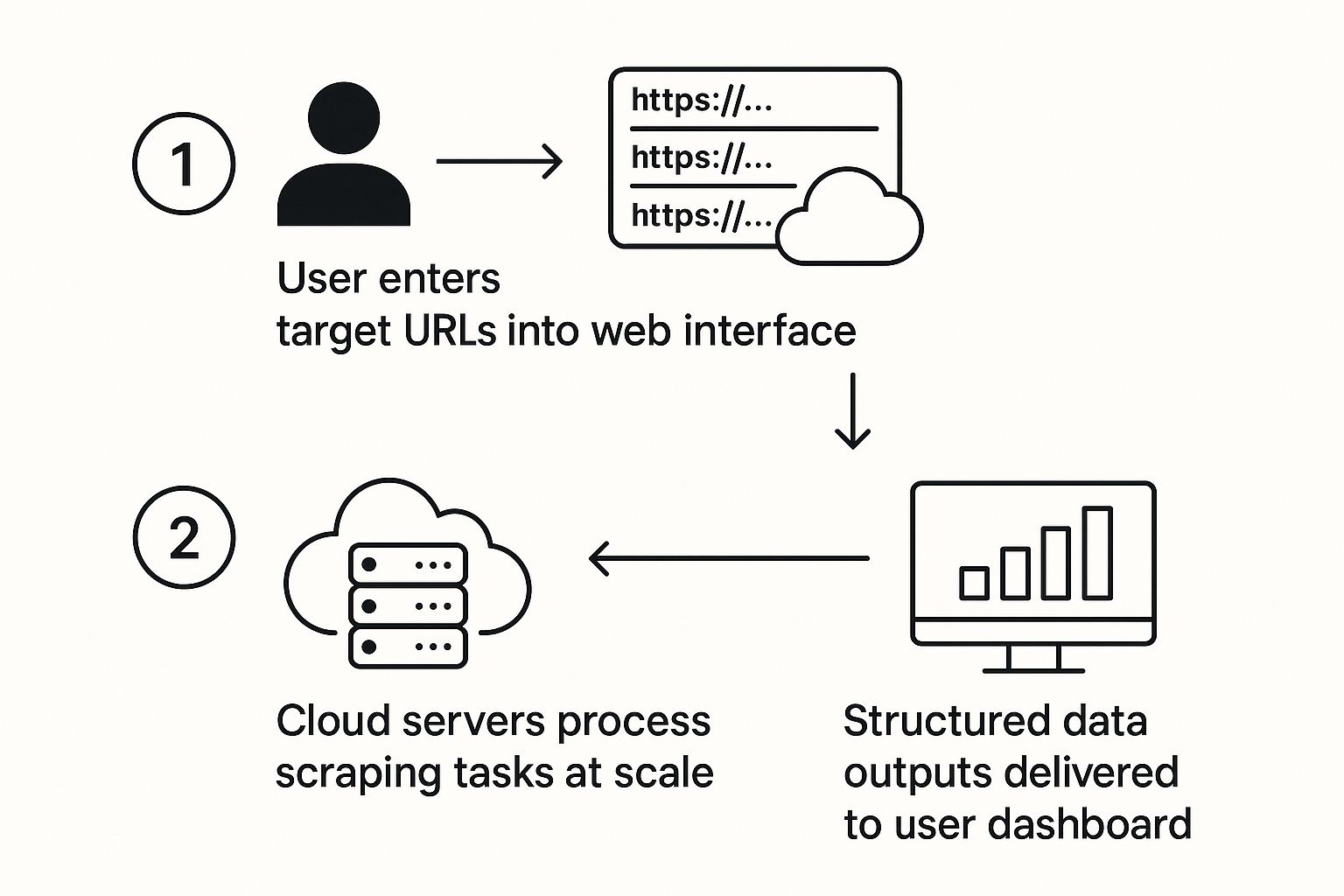
This visual really gets to the heart of a cloud scraper's value. It shows how all the complicated, distributed grunt work is hidden= away, leaving you with a simple, three-step journey.
Defining the Mission in the Dashboard
The whole thing kicks off not in a code editor, but in a clean, user-friendly web dashboard. This is where you lay out the scope of your scraping job. You'd start by feeding it a list of your target electronics retailers' websites, or maybe even specific product category pages.
Next, you tell the scraper what data to grab, usually with a visual, point-and-click tool. You’d just click on the key data points on a sample page:
- Product Name: The main H1 title of the item.
- Price: The current selling price.
- SKU: The unique stock-keeping unit.
- Specifications: Details like screen size, RAM, and storage.
You can then set the job to run on a schedule—daily, in this case—to make sure your comparison site always has the freshest data. With one last click to launch the job, you’ve handed everything off to the cloud platform.
Intelligent Distribution to Worker Nodes
The second you hit "submit," the central system—the brains of the operation—jumps into action. It doesn't just send one server to do all the work. Instead, it smartly breaks your list of dozens of websites down into hundreds, or even thousands, of tiny micro-tasks.
Each of these micro-tasks, like "get the price of this specific laptop from this URL," is then fired off to a huge network of "worker nodes." These are the globally scattered servers that do the actual scraping. This distribution is the secret sauce for achieving both incredible speed and stealth.
A single computer trying to scrape 50 retail sites is like one person trying to interview 50 people in a room all at once—it's just chaos. A cloud scraper is like sending 50 different interviewers, one for each person, to gather information quietly and all at the same time.
Execution and Data Collection
Each worker node grabs its micro-task and gets to work. To fly under the radar and avoid getting blocked, it routes its request through a unique proxy IP address. A worker in Virginia might be fetching data from one retailer, while another in Frankfurt scrapes a European site. To the target websites, this just looks like normal traffic from individual shoppers all over the world.
The worker node downloads the raw HTML of the product page. For modern sites that use a lot of JavaScript to load their content, a headless browser might be used to fully render the page just like a real user would before grabbing the HTML. Many web scraping tools now integrate powerful browser automation libraries. If you're a developer curious about the tech, learning how to run Puppeteer on a server gives you a great look at how this is done.
Parsing, Structuring, and Delivery
The raw HTML collected by all the different workers is sent back to the central system. But this raw data is a mess; it's just code. The system's parsing engine then steps in to pull out the specific data points you defined at the very beginning.
Using the rules you set up in the dashboard, the parser sifts through the HTML to find and isolate the product name, price, and specs. It scrubs the data clean, getting rid of any stray code or weird formatting, and organizes it all into a clean, structured format like JSON or CSV.
Finally, this beautifully structured data is ready to go. The completed dataset can be automatically pushed to your database, sent to a cloud storage bucket, or made available for you to download through a simple API. Your price comparison website now has a steady stream of fresh, organized data, and you never had to manage a single server or write a line of complicated code.
All the theory is great, but the real magic of a cloud-based web scraper happens when it starts solving actual business problems. This isn't just some abstract tool for developers; it's a strategic weapon that creates real, measurable value across just about every industry you can think of.
Companies in e-commerce, finance, and beyond are using cloud scrapers to gather intelligence, fine-tune their pricing, and spot trends long before their competitors even know what's happening. Let's look at a few scenarios where this technology is making a huge difference.
E-commerce Price and Stock Monitoring
For any online retailer, the digital marketplace is a pricing battlefield. Imagine a mid-sized electronics store trying to keep up. They were manually checking competitor prices for their top 500 products, a task that was slow, riddled with errors, and burned dozens of hours every single week. By the time they updated their own prices, the market had already moved on.
They turned things around by setting up a cloud-based web scraper to automatically keep an eye on key competitor sites.
- The Problem: They couldn't track competitor pricing and stock levels in real-time. This meant they were constantly losing sales and putting out uncompetitive offers.
- The Solution: They deployed a scheduled scraping job to run every three hours. It pulled product prices, discounts, and stock availability from ten of their biggest competitors, feeding that structured data directly into their pricing analytics dashboard.
- The Outcome: The result was a 15% increase in sales for their key product lines in the first quarter alone. They could finally react instantly to price drops and stock shortages, making sure their offers were always right on the money.
Alternative Data for Financial Analysis
In the high-stakes world of finance, even a tiny edge can be worth millions. A boutique investment firm was on the hunt for "alternative data" sources—anything that could help predict a company's performance beyond the usual financial reports. Their theory? Tracking the global movement of shipping containers could forecast the quarterly earnings of major import/export companies.
The challenge was gathering this data on a global scale. Manually tracking thousands of shipments from various port authority websites was completely out of the question. They needed an automated, reliable way to collect this information 24/7.
A cloud-based web scraper became their secret weapon. The firm built a sophisticated scraping operation to pull data from logistics and maritime traffic websites. The system gathered container locations, vessel speeds, and port docking times, turning raw, unstructured web data into powerful, predictive financial signals. This innovative approach is part of a huge trend; the global web scraper software market was valued at USD 718.86 million in 2024 and is projected to smash USD 2.2 billion by 2033. You can explore detailed web scraper market research on straitsresearch.com to see the full breakdown.
Market Trend Analysis in Real Estate
A regional real estate agency was getting left behind by a fast-moving housing market. Their agents were working off outdated monthly reports, which meant they were missing out on emerging neighborhood hotspots and critical pricing trends. To give better advice and stay competitive, they had to get ahead of the curve.
The agency fired up a cloud scraper to aggregate property listings from dozens of national and local real estate websites every single day. This gave them a unified, near real-time database of the entire regional market.
- Problem Identified: They were relying on old, lagging market data, making it impossible to spot new investment opportunities or advise clients on what a property was really worth today.
- Scraping Solution: A daily scraping job collected data on new listings, price changes, how long properties were on the market, and final sale prices.
- Measurable Result: The agency identified three up-and-coming neighborhoods a full six months before they were mentioned in official industry reports. This insight helped their clients make smarter, more profitable investments, cementing the agency's reputation as a true market leader.
Picking the right cloud-based web scraper can feel like trying to find the right tool in a massive, unfamiliar toolbox. You've got dozens of options, and they all claim to be the best. But the truth is, the "best" tool completely depends on what you're trying to build.
A small startup just dipping its toes into market research has wildly different needs than a hedge fund that requires high-frequency financial data yesterday. The perfect solution for one is often a terrible fit for the other.
So, how do you make the right call? It all starts with a clear-eyed look at your own needs. Before you even glance at a pricing page, you need to nail down the scale of your project, your team's technical chops, and exactly what kind of data you're chasing.
Your Technical Skill Level and Interface
The first big decision point is the user interface. Are you looking for a simple point-and-click solution, or does your team need a powerful API to hook into? This really just comes down to how comfortable your team is with code.
- No-Code Interfaces: These are visual, intuitive platforms that let anyone build a scraper without writing a single line of code. They're a godsend for marketing teams, business analysts, or founders who need data fast without roping in a developer. A practical example would be a marketing analyst using a no-code tool to extract customer reviews for a competitor's product by simply clicking on the review text, star rating, and author name on the page.
- Developer-Friendly APIs: On the other hand, if you have developers ready to get their hands dirty, an API offers ultimate power and flexibility. This lets you bake the scraping engine right into your own applications, giving you precise control over every single request and workflow. For example, a developer could use a scraping API to build a custom application that automatically enriches new user sign-ups with public data from their professional profiles.
The right interface is all about empowering your team, not creating a bottleneck. The goal is to get the data you need with the least amount of friction, whether that’s through a simple dashboard or a powerful API.
Proxy Network Quality and Type
Let's be clear: the proxy network is the absolute backbone of any serious scraping operation. It's what keeps you from getting blocked, and its quality is non-negotiable. The type of proxies a service offers can single-handedly determine whether your project succeeds or fails.
You'll generally run into two main types:
- Datacenter Proxies: These are IP addresses that come from cloud servers. They're fast, cheap, and work great for hitting websites with basic security. A good use case is scraping public business directories or government databases.
- Residential Proxies: These are the real deal—IP addresses from actual Internet Service Providers (ISPs), making your requests look like they're coming from a regular home user. They're essential for getting into heavily fortified websites that can spot and block datacenter IPs from a mile away. For instance, scraping flight prices from an airline website, which uses advanced bot detection, would almost certainly require residential proxies.
If you're a small business scraping public directories, datacenter proxies will probably do the trick. But if you're an e-commerce company trying to track competitor prices on sophisticated platforms, you'll need a rock-solid residential proxy network to get consistent, reliable data.
Data Quality and Integration Options
Finally, think about what happens after the data is scraped. A top-tier cloud-based web scraper doesn't just dump a pile of raw HTML on your doorstep. It delivers clean, structured data and makes it ridiculously easy to plug into your systems.
Look for services that guarantee data quality with features like built-in validation and cleaning. Just as important, check out how you can actually get your hands on the data. Do they offer webhooks for real-time updates? Direct database integrations? Simple CSV or JSON downloads? The easier it is to pipe that data into your existing tools, the more valuable the scraper becomes. For example, a service that offers a direct integration with Google Sheets allows a marketing team to get daily updates on social media trends without any manual data entry.
Of course, having the right infrastructure to handle this data flow is just as critical. You can explore a variety of cloud services and servers to find the perfect home for your data pipeline.
Common Questions About Cloud Scrapers
When you're first diving into cloud-based web scrapers, a few questions always seem to pop up. Let's tackle them head-on, so you can move forward with confidence and get straight to the data.
Is Web Scraping Actually Legal?
This is usually the first thing on everyone's mind. The short answer is yes, but with some important caveats. Scraping publicly available data is generally considered legal. The landmark hiQ Labs vs. LinkedIn case set a major precedent, establishing that accessing public data doesn't violate the Computer Fraud and Abuse Act (CFAA).
But here’s where it gets nuanced. It all comes down to what you scrape and how you do it. To stay on the right side of things, you should always steer clear of:
- Scraping copyrighted material.
- Pulling personal data that could run afoul of privacy laws like GDPR.
- Hammering a website's servers with too many requests, which can look like a denial-of-service attack.
A good rule of thumb is to always respect a website's
robots.txtfile and its Terms of Service. Ethical scraping isn't just about avoiding legal headaches—it's about being a good citizen of the web.
What Kind of Technical Skills Do I Need?
The great news is that the barrier to entry has never been lower. You absolutely do not need to be a coding guru to use a cloud based web scraper. The skill level required= really just depends on the tool you pick.
Many of today's top platforms are built with no-code interfaces, letting you point and click your way to a powerful scraper. A business analyst or marketer can get a sophisticated data extraction project running in minutes, all without writing a single line of code.
For developers who want more control, the same services offer powerful APIs for deep customization and integration. So, whether you're a total beginner or a seasoned engineer, there's a path for you.
How Do Cloud Scrapers Get Around Anti-Scraping Tech?
Websites are getting smarter about blocking bots, and that's precisely where a cloud based web scraper proves its worth. These services are built from the ground up to handle the cat-and-mouse game of anti-scraping measures.
The most common defense is simple IP blocking. A cloud scraper sidesteps this easily by using a massive, rotating proxy network. Your requests come from thousands of different IP addresses, making it nearly impossible for a website to pin you down and block you.
What about trickier challenges, like CAPTCHAs?
This is another huge advantage. Many premium cloud scraping platforms have integrated, automated CAPTCHA solvers. The system detects when a CAPTCHA pops up and solves it behind the scenes, without you having to lift a finger. This keeps your data jobs running smoothly 24/7, even on highly protected sites. It's this automated handling of complex roadblocks that sets a professional cloud service miles apart from a simple, locally-run script.
Ready to harness the power of AI-driven tools and servers? At FindMCPServers, we provide the resources and community to help you discover and integrate the best MCP servers for your projects. Explore our platform today and take your AI capabilities to the next level.