Building a Python Twitter scraper is one of the best ways to collect public data directly from the source, especially when the official API just won't cut it. It hands you the keys, giving you total control over the data you pull—whether that’s a specific user’s timeline or a broad search for a trending keyword—without bumping into the usual API roadblocks.
So, Why Build Your Own Twitter Scraper Anyway?
Look, the official Twitter (now X) API has its place. It’s structured, and it works. But for any kind of large-scale or niche research project, you’ll hit a wall pretty fast. The two biggest headaches are the strict rate limits and the eye-watering costs that come with the premium tiers.
If you’re a developer, data scientist, or marketer who needs a lot of data, the official API quickly becomes impractical. That’s exactly when building your own scraper in Python starts to look like a brilliant move.
A custom scraper gets you straight to the public data without the gatekeepers. You're not boxed in by pre-set API endpoints or a pricing model that nickels and dimes you for every request. Instead, you build a tool that’s perfectly tuned to grab exactly what you need. Simple as that.
Tapping into Deeper Insights
Data pros are already using custom scrapers to pull out all sorts of valuable intel. It’s not just theoretical; here’s what that looks like in the real world:
- Market Trend Analysis: Imagine a financial analyst setting up a scraper to watch tweets that mention certain stocks or cryptocurrencies. They could get a real-time pulse on market sentiment to help guide their trading decisions.
- Brand Sentiment Tracking: Marketing teams can dive deep into conversations about their brand or their competitors. A scraper can uncover customer frustrations or positive feedback that standard analytics tools would completely miss.
- Academic Research: A sociologist studying a social movement could scrape public posts to see how the narrative evolves, who the key players are, and how the movement spreads geographically over time.
Building your own scraper isn't just about dodging API fees. It's about giving yourself the freedom to explore data on your own terms, which opens the door to far more creative and in-depth analysis.
Python-based Twitter scrapers have become go-to tools for anyone serious about data, especially with X (formerly Twitter) projected to have over 556 million monthly active users by 2025. These scrapers are workhorses, automating the process of pulling tweets, user profiles, and engagement stats without touching the API.
With hundreds of millions of tweets posted every single day, powerful libraries like Playwright are essential. They let you mimic real user behavior—like endlessly scrolling a feed—to dig up both historical and real-time data efficiently. If you want to learn more about how Python scrapers are used for big data, check out the full guide on Thunderbit.
Choosing the Right Python Scraping Library
Picking the right tool for your python twitter scraper is probably the most critical decision you'll make right at the start. It's a choice that ripples through your entire project, defining everything from the initial setup and your data collection limits to how often you'll need to patch things up when Twitter changes something.
Simply put, your project's success rides on matching the tool to the task. The scraping world is pretty much split into two camps: libraries that play by the rules using the official API, and those that go their own way. Each has its place.
The Official API Route with Tweepy
If you're lucky enough to have access to the Twitter (now X) API, a library like Tweepy is a solid, popular choice. It's essentially a friendly wrapper for the official API, which makes pulling clean, structured data a breeze. This approach is reliable and, most importantly, officially sanctioned. That’s a huge plus for any project that needs to stay "by the book."
Here's a quick practical example of how you might use Tweepy to fetch a user's timeline. You would first need to get your API keys from the Twitter Developer Portal.
import tweepy
# Authenticate to Twitter
# (Replace with your actual keys and tokens)
auth = tweepy.OAuth1UserHandler(
"YOUR_API_KEY", "YOUR_API_SECRET",
"YOUR_ACCESS_TOKEN", "YOUR_ACCESS_TOKEN_SECRET"
)
api = tweepy.API(auth)
# Fetch recent tweets from a user's timeline
for tweet in api.user_timeline(screen_name='TwitterDev', count=10):
print(f"- {tweet.text}\n")
But here's the catch: the API has some serious limitations. You'll run headfirst into strict rate limits, which put a hard cap on how many requests you can send in a certain amount of time. Some endpoints might only let you make a few hundred requests every 15 minutes. This makes Tweepy a non-starter for any kind of large-scale data collection.
This decision tree gives you a visual on the initial setup, which you'd follow for a library like Tweepy.
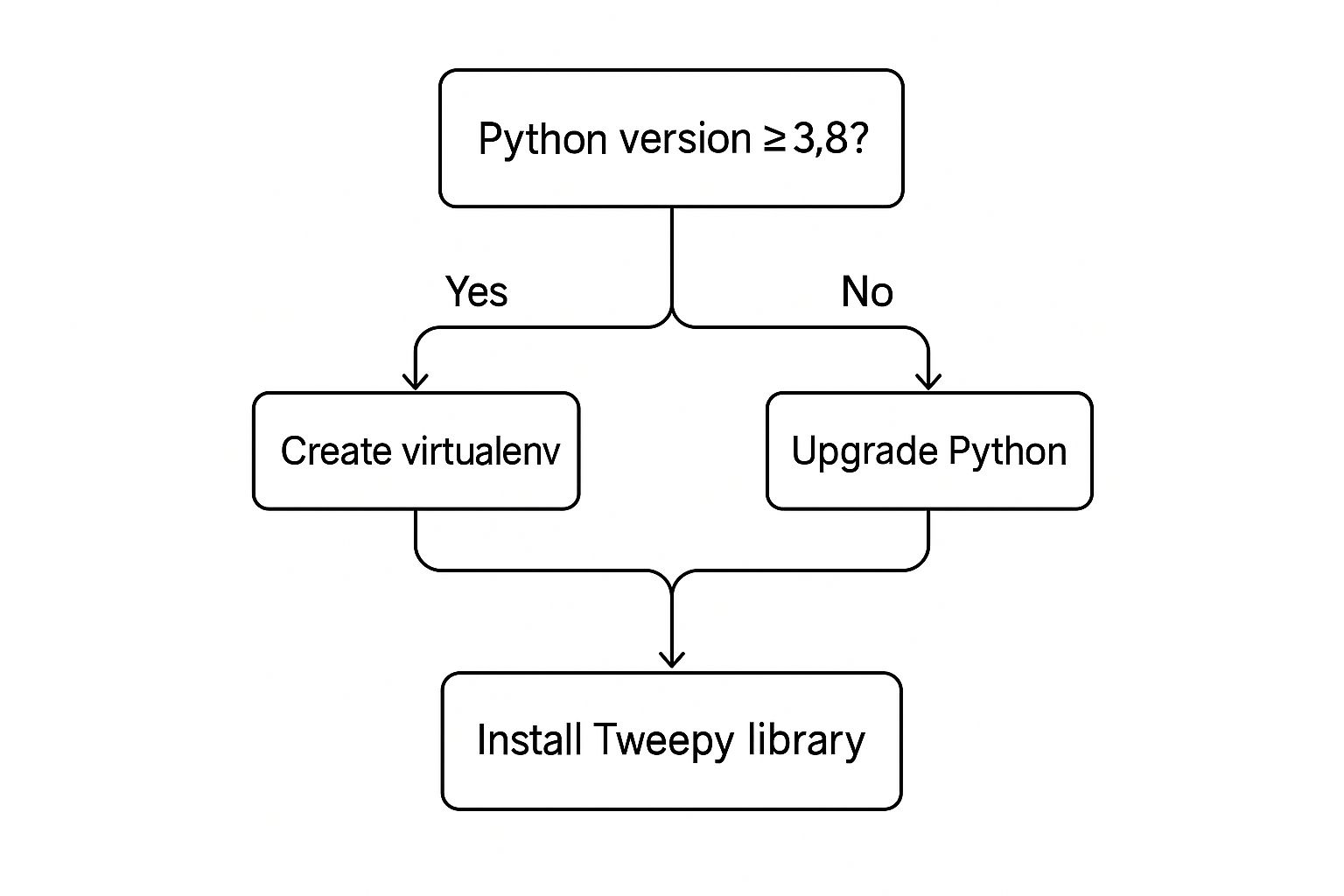
As you can see, a modern version of Python and a clean virtual environment are the foundational first steps before you even think about installing packages.
Bypassing Limits with Snscrape
What if you need a mountain of historical data and don't have API keys? That's where Snscrape comes in. It's the go-to solution for developers who need to dig deep into Twitter's archives.
Instead of talking to the API, Snscrape scrapes the public-facing website directly. This clever workaround means you get to bypass all of the API's rate limits and access restrictions. For researchers or analysts needing to scrape millions of tweets, this is an absolute game-changer.
The trade-off, however, is fragility. Because it's tied to the website's HTML structure, any front-end update from Twitter can break the library. When that happens, you're usually waiting on the open-source community to push a fix.
Python Twitter Scraping Libraries Compared
Choosing between these libraries often feels like a fork in the road. To make it easier, here's a direct comparison to help you figure out which path is right for your project.
| Library | Method | Best For | Key Limitation |
|---|---|---|---|
| Tweepy | Official API Wrapper | Small, targeted data collection with API keys. | Strict rate limits and access restrictions. |
| Snscrape | No-API Web Scraping | Large-scale, historical data collection without API keys. | Can break with website updates; less "official". |
This table lays out the core differences. Your choice really boils down to whether you prioritize official, stable access for smaller datasets or unrestricted access for massive ones.
My two cents: If you have API access and just need to grab a small, specific set of tweets, stick with Tweepy. It's the safe, reliable bet. But for any project that involves large-scale, historical data mining without an API key, Snscrape is the undisputed champion, even with its occasional maintenance needs.
Ultimately, picking the right library is about knowing your project's goals. Before you write a single line of code, ask yourself:
- How much data do I really need? Are we talking thousands of tweets, or millions?
- Do I have API access? This is a simple yes or no that changes everything.
- Am I digging into the past? Do you need tweets from several years ago?
- What's my maintenance tolerance? Are you okay with updating your code if the platform changes?
Answering these questions first will point you directly to the right tool and get your scraping project off to a running start. And for developers looking to broaden their skills, our guide to the best AI developer tools is a great resource for tackling more advanced projects.
How to Scrape Tweets Using Snscrape
Alright, time to get our hands dirty and build a functional python twitter scraper with Snscrape. This library is a powerhouse. The real magic is that it works without needing any API keys, letting you pull huge amounts of public data that would otherwise be a pain to access.
We’ll walk through everything from getting it installed to exporting all that juicy data into a clean CSV file.
First things first, let's get Snscrape set up in your Python environment. Twitter is always changing things on their end, and the Snscrape developers are constantly updating the library to keep up. Because of this, it's a good idea to install it directly from the GitHub repository to make sure you have the latest and greatest version.
You can pull it in with a single pip command right in your terminal:
pip install git+https://github.com/JustAnotherArchivist/snscrape.git
We'll also need the Pandas library to help us organize and save the data we scrape. If you don't have it installed, just run pip install pandas. Once those two are ready, we can jump into the code.
Building Your First Scraper
Let's start with a really common task: scraping the most recent tweets from a specific user's timeline. This is the perfect way to get a feel for how Snscrape works before we tackle more complex queries.
The process is pretty simple. We'll import the modules we need, tell the script which user we're targeting, and then loop= through the scraper's output to grab the tweets one by one. I like to store the results in a list of dictionaries as I go.
Here’s a real-world example of how to grab the latest 200 tweets from a public account like @elonmusk.
import snscrape.modules.twitter as sntwitter
import pandas as pd
# Create an empty list to store our tweet data
tweets_list = []
# Define the user and how many tweets we want
username = 'elonmusk'
tweet_limit = 200
# We'll use the TwitterUserScraper to get tweets from a specific user
for i, tweet in enumerate(sntwitter.TwitterUserScraper(username).get_items()):
if i >= tweet_limit:
break
tweets_list.append([tweet.date, tweet.id, tweet.rawContent, tweet.user.username])
# Create a pandas DataFrame from our list of tweets
tweets_df = pd.DataFrame(tweets_list, columns=['Datetime', 'Tweet Id', 'Text', 'Username'])
# Check out the first 5 rows of our DataFrame
print(tweets_df.head())
# And finally, save it to a CSV file
tweets_df.to_csv(f'{username}_tweets.csv', index=False)
This script kicks off the TwitterUserScraper with our target username, loops through the tweets, and stops once it hits the limit we set. Then, it hands everything over to Pandas to structure the data and save it as elonmusk_tweets.csv. Simple as that.
Searching for Keywords and Hashtags
Scraping a single user is useful, but the true power of a python twitter scraper is digging into specific topics across the entire platform. It's super easy to adapt our script to search for keywords, hashtags, or specific phrases.
To do this, we just need to swap out TwitterUserScraper for TwitterSearchScraper. This lets you feed it a search query just like you would on the Twitter website itself. You could use this to track mentions of a new product, monitor a political event, or see what people are saying about a trending hashtag.
The key is crafting a precise search query. You can use all the standard Twitter search operators like
since:,until:,#hashtag, or"exact phrase"directly in your Snscrape query string. This is crucial for narrowing down your results and getting exactly the data you need.
Let's say you want to find 500 recent tweets mentioning "#AI" since the start of 2024. The code looks almost identical, we just change the scraper object.
import snscrape.modules.twitter as sntwitter
import pandas as pd
tweets_list = []
query = "#AI since:2024-01-01"
tweet_limit = 500
for i, tweet in enumerate(sntwitter.TwitterSearchScraper(query).get_items()):
if i >= tweet_limit:
break
tweets_list.append([tweet.date, tweet.id, tweet.rawContent, tweet.user.username])
tweets_df = pd.DataFrame(tweets_list, columns=['Datetime', 'Tweet Id', 'Text', 'Username'])
tweets_df.to_csv('AI_hashtag_tweets.csv', index=False)
print("Scraping finished and data saved to AI_hashtag_tweets.csv")
With that one small change, we've pivoted from scraping a single user to collecting data on a specific topic. The output CSV file will now be filled with tweets from all kinds of users who match our search.
Sometimes, the text data you pull can be a bit messy. For more advanced text cleaning, our guide on Python fuzzy string matching covers some powerful techniques for handling messy text. This kind of flexibility is what makes Snscrape such an incredibly versatile tool for any data project.
Putting Your Scraped Data to Work

Alright, you've built your python twitter scraper and have a nice pile of raw data. This is where the real fun begins. Collecting tweets is just the first step; the magic happens when you turn that noisy stream of text into something you can actually use.
A classic example is tracking brand sentiment or customer feedback. Imagine you're a marketer who just launched a new product. You could scrape thousands of tweets to see how people are reacting.
Maybe you find out that while everyone loves a new feature, a solid 30% of users are complaining about the price. That’s a powerful insight that can directly influence your marketing strategy. You're essentially transforming public chatter into a clear signal, letting you spot user concerns and get ahead of them. You can check out more professional use cases for Twitter scrapers to see just how versatile this can be.
Cleaning and Preparing Your Data
Before you can spot any meaningful patterns, you have to clean house. Raw tweet data is notoriously messy—it’s full of URLs, mentions, and hashtags that will skew your analysis. This is where the Pandas library becomes your best friend.
Let's take the AI_hashtag_tweets.csv file we created earlier. With just a few lines of code, we can load it up and perform some basic cleaning.
import pandas as pd
import re
# Load the scraped data
df = pd.read_csv('AI_hashtag_tweets.csv')
def clean_tweet_text(text):
text = re.sub(r'http\S+', '', text) # Remove URLs
text = re.sub(r'@\w+', '', text) # Remove mentions
text = re.sub(r'#', '', text) # Remove the '#' symbol
text = re.sub(r'RT[\s]+', '', text) # Remove RT
text = text.strip()
return text
# Apply the cleaning function to our 'Text' column
df['Clean_Text'] = df['Text'].apply(clean_tweet_text)
print(df[['Text', 'Clean_Text']].head())
This simple script adds a new Clean_Text column to our DataFrame. Now you have a much tidier version of the tweet content, which is exactly what you need for any real analysis.
Visualizing Your Findings
With clean data in hand, you can start hunting for trends. One of the best ways to understand and share your findings is by visualizing them. Libraries like Matplotlib or Seaborn let you create compelling charts that tell a story at a glance.
For instance, you could track the frequency of tweets over time to pinpoint when a topic was buzzing. Here's a practical example of how to plot the number of tweets per day.
import pandas as pd
import matplotlib.pyplot as plt
# Load the data (assuming it's already cleaned)
df = pd.read_csv('AI_hashtag_tweets.csv')
# Convert 'Datetime' column to datetime objects
df['Datetime'] = pd.to_datetime(df['Datetime'])
# Set 'Datetime' as the index
df.set_index('Datetime', inplace=True)
# Resample by day and count the number of tweets
tweets_per_day = df['Tweet Id'].resample('D').count()
# Plot the results
plt.figure(figsize=(12, 6))
tweets_per_day.plot(kind='bar', color='skyblue')
plt.title('Number of Tweets Mentioning #AI per Day')
plt.xlabel('Date')
plt.ylabel('Number of Tweets')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
A great starting point is to plot a simple time series. By converting the 'Datetime' column to a proper datetime object and resampling the data, you can easily create a bar chart showing the daily volume of tweets. This visual can instantly reveal spikes in conversation, which almost always correspond to real-world events.
With these analysis techniques, your Python scraper evolves from a simple data-gathering script into a powerful research and intelligence engine.
Scraping Ethically and Effectively
Building a powerful python twitter scraper hands you the keys to an incredible kingdom of public data. But with that power comes a serious responsibility. Scraping ethically isn’t just about being a good digital citizen—it's a practical necessity to keep your scraper from getting blocked and to make sure your project can actually last.
The golden rule? Scrape with respect.
Think of it like being a guest at someone's party. You wouldn't want to break things or cause a scene, and the same logic applies to a website's servers. The best way to do this is to build that politeness directly into your code.
One of the easiest and most important techniques is simply adding a delay between your requests. Hitting the server with hundreds of requests in a few seconds is a dead giveaway you're a bot, and it's the fastest way to get your IP address banned.
Respecting the Rules and Blending In
Even though you’re not using the official API, you should still pay attention to Twitter’s terms of service and its robots.txt file. While robots.txt isn't legally binding, it’s a clear sign of what the site owner is okay with. Ignoring it is like waving a giant red flag that says, "look at me!"
To make your scraper look less like an aggressive bot and more like a regular user, try these practical steps:
- Add Delays: This is non-negotiable. Use Python's
time.sleep()function to pause your script for a few seconds between requests. To really mimic human behavior, make the delay random. No human clicks at a perfectly consistent interval. Here's a quick example:import time import random # In your scraping loop # time.sleep(random.uniform(1, 4)) # Pauses for a random time between 1 and 4 seconds - Rotate User Agents: A user agent is a piece of text that tells a server which browser you’re using. If every single one of your requests comes from the default Python user agent, it's an obvious sign of automation. Keep a list of common user agents from real browsers (like Chrome, Firefox, and Safari) and cycle through them.
- Stick to Public Data: This is a hard line you should never cross. Only scrape information that is publicly visible and doesn't require a login. Trying to get behind a login wall is not only unethical but also a serious violation of terms.
Your goal is to gather data without ruining the service for everyone else. A well-behaved, patient scraper is a long-lasting scraper. If you overload servers or ignore clear guidelines, you’ll just get cut off.
Handling Data Responsibly
Your ethical duties don't stop once you have the data. The information you've gathered, even if it's public, is still tied to real people. That means data privacy has to be a top priority.
If you plan on publishing your findings or building a dataset, take the time to anonymize any personally identifiable information (PII). This could mean stripping out usernames or any other detail that could directly link a tweet back to an individual.
Responsible data handling is a cornerstone of good data science. It builds trust and adds credibility to your work. For AI developers dealing with complex data integrations, understanding a structured approach like the Model Context Protocol can offer valuable insights, as it standardizes how models interact with external tools and data sources.
Common Questions About Python Twitter Scraping
As you start building your own python twitter scraper, you'll probably hit a few snags or have questions pop up. It happens to everyone. This section tackles some of the most common issues head-on to help you troubleshoot and get a clearer picture of the web scraping landscape.
Is It Legal to Scrape Twitter?
This is the big one, and honestly, the answer lives in a bit of a gray area. Generally, scraping data that's publicly available is considered legal. The crucial rule of thumb is to be respectful and ethical—never try to scrape private data or anything behind a login wall.
Always take a look at the platform's current Terms of Service. If you're planning to use this data for any commercial purpose, your safest bet is to chat with a legal professional first. The methods in this guide are strictly for research and analysis of public information.
Why Not Just Use the Official API?
The official Twitter (now X) API can be a decent tool, but it's often a non-starter for serious data collection projects because of its limitations.
- Strict Rate Limits: The API puts a hard cap on how many requests you can fire off in a set amount of time. This can seriously slow down any large-scale data gathering.
- High Costs: Want access to more data or premium features? It gets expensive, fast.
- Limited Historical Data: Digging into a deep archive of older tweets is often restricted or locked behind a hefty paywall.
This is where a library like Snscrape shines. It works by scraping the public website directly, which lets you access a massive amount of historical data without needing API keys or sweating over request limits.
How Can I Avoid Getting Blocked?
The best way to avoid getting your IP address blocked is to make your scraper act more like a human and less like a bot. If your script is hammering the server with hundreds of requests a minute, it’s going to raise some obvious red flags.
The most effective strategy is to combine a few different techniques. Mix in random delays between requests with
time.sleep(), rotate your user agent to look like you're coming from different browsers, and for any serious scraping, use a rotating proxy service to spread your requests across multiple= IP addresses.
Can I Still Scrape After Platform Changes?
Yes, but you have to be ready to adapt. Social media sites like X are constantly tweaking their website's code. An update can instantly break a scraper that's built to look for a specific HTML structure.
This is exactly why using a well-maintained library like Snscrape is so important. Its community is usually quick to release patches and updates to handle these changes. Think of it as a constant cat-and-mouse game; you'll need to be prepared to update your code or library versions to keep your scraper running smoothly.
At FindMCPServers, we're dedicated to helping developers connect AI models with powerful external tools. Explore our platform to discover MCP servers that can supercharge your next data-driven project: https://www.findmcpservers.com.