When you browse a website, stream a movie, or check your email, you're interacting with one of the most fundamental concepts of the modern internet: the client-server architecture. It's the invisible framework that makes our digital world tick.
At its heart, this model is a simple, powerful idea. A client—like your laptop or smartphone—asks for something, and a server—a powerful computer somewhere else in the world—provides it. For example, when you open the Spotify app on your phone (the client) and search for a song, your phone sends a request to Spotify's servers. The server finds the song in its massive music library and streams it back to your phone. It’s a digital conversation, a constant back-and-forth of requests and responses that happens millions of times a second.
Understanding the Client Server Model
The whole point of the client-server model is to smartly divide up the work. Instead of your phone needing to store every video on YouTube, it just needs to know how to ask for the one you want to watch. This separation of concerns is what allows the internet to be so vast, fast, and reliable. The heavy lifting is handled by specialized machines, while our personal devices stay lightweight and easy to use.
Let's use a restaurant analogy. You, the customer, are the client. You don't need to know how the kitchen is run, where the ingredients come from, or how to cook the perfect steak. You just need a menu to make a request: "I'll have the burger and fries, please."
The waiter carries your request to the kitchen, which is the server. The kitchen has all the ingredients, the fancy equipment, and the expert chefs needed to prepare your meal. It fulfills your request and sends the finished dish back to your table. You get exactly what you asked for without ever seeing the complex process behind the scenes. That's a perfect parallel to what happens when you type a web address into your browser.
The Key Players in This Model
This digital restaurant runs on three essential components working in harmony:
-
Clients: These are our everyday devices—laptops, smartphones, smart TVs, you name it. They run applications like web browsers or mobile apps that act as the customer, initiating requests for information or services. A practical example is the Gmail app on your phone, which acts as a client to request your latest emails.
-
Servers: Think of these as super-powered, always-on computers built for one purpose: to store, process, and manage data. They sit in data centers, waiting patiently to "serve" up websites, videos, or application data to clients anywhere in the world. For instance, Netflix operates a vast network of servers that store and stream movie files to millions of users simultaneously. A single server can handle requests from thousands of clients at once.
-
The Network: This is the communication highway connecting clients and servers, usually the internet. It's the waiter in our analogy, dutifully carrying requests from your table to the kitchen and bringing the final dish back. Your home Wi-Fi and the global network of undersea cables are all part of this network.
To make it even clearer, let's break down the distinct roles of the client and the server.
Client vs Server At a Glance
The following table offers a quick comparison, using our restaurant analogy to highlight the different responsibilities each one holds.
| Characteristic | Client (The Customer) | Server (The Kitchen) |
|---|---|---|
| Role | Initiates requests for data or services. | Listens for and responds to client requests. |
| Visibility | The part the user directly interacts with (UI). | The "behind-the-scenes" part of the operation. |
| Lifespan | Active only when the user needs it. | Always on and available to respond. |
| Knowledge | Doesn't need to know how the work is done. | Holds all the data, logic, and resources. |
| Communication | Sends a request and waits for a response. | Receives a request, processes it, and sends a response. |
| Example | Your web browser asking for a webpage. | The web server hosting the files for that webpage. |
Ultimately, this relationship defines how most modern applications are built.
A simple rule of thumb is that clients start the conversation, and servers are there to listen and reply. The client is the active participant making the first move, while the server is the reactive one, ready to fulfill the request.
This model isn't just for websites. It’s the engine behind online gaming, banking apps, and collaboration tools like Google Docs. Every time, your device (the client) is asking for data from a company's server, which then delivers the content you need. This elegant division of labor is truly the backbone of our connected lives.
How Clients and Servers Actually Communicate

The conversation between a client and a server isn't just a random exchange of data. It’s a highly structured dialogue, a digital back-and-forth that follows a clear pattern. Think of it like ordering food at a restaurant—you make a specific request, and the kitchen sends back exactly what you asked for.
This whole process, from the moment you click a link to the second a webpage appears, is driven by the request-response cycle. It’s the foundational loop that makes almost everything on the internet work.
Let’s walk through a simple, everyday example: loading a website. Your web browser is the client, and it needs to ask the server for the page's content. It does this by creating a formal request, almost like filling out a digital order form. This request is formatted using a specific set of rules, or a protocol—usually the Hypertext Transfer Protocol (HTTP).
This HTTP request is incredibly specific. It contains the server’s address (the URL), what it wants the server to do (like a GET action to retrieve the page), and other key details. Your browser then shoots this message across the network to find the right server.
The Server's Side of the Story
Once that request hits the server, a machine specifically designed to handle these queries springs into action. It’s not a messy free-for-all; servers are built to juggle thousands of these requests at once without getting them confused.
The server's software reads the HTTP request to figure out what the client needs. If it's a webpage, the server typically performs a few key tasks:
- Finding the Right Files: It locates the necessary files, like the main HTML document that provides the page's backbone.
- Running a Little Logic: For dynamic websites, the server might need to run a script to fetch fresh data from a database—think of a blog pulling up its latest posts or a social media feed loading your friends' new updates.
- Putting it All Together: The server gathers all the pieces—HTML for structure, CSS for looks, and JavaScript for interactive elements.
After all that work, the server bundles everything into an HTTP response. This package includes a status code (like the famous 200 OK for success or 404 Not Found for an error) along with all the content you asked for. It sends this back across the network to your browser, which then unpacks the files, pieces them together, and renders the webpage on your screen. And just like that, the cycle is complete.
The request-response cycle is the heartbeat of the client-server model. Every single action—clicking a link, submitting a form, loading an image—kicks off this same fundamental process of a client asking and a server answering.
Juggling Thousands of Connections
So, how can a single server manage a flood of requests from different users all at once? It’s a mix of powerful hardware and clever software that excels at multitasking. Each incoming request is neatly placed in a queue and processed in order, often in just milliseconds. For example, during an online flash sale, an e-commerce server might handle thousands of "add to cart" requests per second, ensuring each customer's order is processed correctly without mixing them up. This efficiency is what ensures everyone gets the right response quickly.
This architecture isn't just for websites, either. In the world of AI, a model (acting as the client) might send a request to a specialized server for a specific dataset or tool. For developers building these AI applications, finding the right servers is key. That’s where platforms listing various MCP servers become so valuable, helping connect them to the specialized resources they need. At its core, it's the same client-server logic powering some of the most advanced tech we have today.
Tracing the Origins of the Client-Server Model
To really get what client-server architecture is all about and why it’s the bedrock of modern computing, we have to jump back in time a bit. Before our desks and pockets held powerful computers, the digital world was a very different place. It was ruled by massive mainframe computers—room-sized machines that housed all the processing muscle and data.
People connected to these behemoths using "dumb terminals." Think of them as just a screen and a keyboard, with practically zero computing power of their own. Every time you hit a key, that single character was sent to the mainframe, processed, and the result was sent all the way back to your screen. It was a slow, clunky, and expensive way to work, tethering everyone to one central machine.
A New Era of Computing
The whole game changed in the 1980s. Two crucial pieces of technology started going mainstream: the personal computer (PC) and local area networks (LANs). All of a sudden, those terminals weren't so "dumb" anymore. People had real processing power sitting right on their desks, turning them into "smart" clients that could run their own programs.
This shift paved the way for a completely new paradigm. As networking got better and faster, the client-server model emerged. The idea was to split an application into two distinct parts: the client software running on a user's PC and the server software handling the data and heavy processing. This new design allowed clients to shoot requests over a network to a powerful, centralized server, which would do the work and send back the results. For a deeper look at this transition, check out this great article on the evolution of software architecture on orkes.io.
The core idea was simple but profound: let the powerful desktop computer (the client) handle the user interface and presentation, while a dedicated, centralized machine (the server) manages the heavy lifting of data storage and complex logic.
This division of labor was a breakthrough. Take a database application, for example. It no longer had to live entirely on a single mainframe. Now, the client application could offer a friendly interface for building queries, while a specialized database server—like the ones you can find in our list of SQL servers—could focus on managing the data efficiently.
The model truly hit its stride with the birth of the World Wide Web in the early 1990s. The web is built entirely on this principle. Your web browser is the client, and when you type in a URL, it sends a request to a web server out on the internet. That simple, scalable concept is the foundation for nearly every digital service we rely on today, from our social media feeds to sprawling cloud applications.
Exploring Different Architectural Tiers
The client-server model isn't a one-size-fits-all solution. Think of it less as a rigid blueprint and more as a foundational concept that can be built out in layers, or "tiers." These tiers represent the logical separation between you (the client) and the data you're trying to access.
How an application is structured into these tiers has a huge impact on its performance, security, and how easily it can grow. Most systems you interact with daily fall into one of three common patterns.
The Simple 2-Tier Architecture
The most direct setup is the 2-tier architecture. In this model, the client talks straight to the server, which is almost always a database. There's no go-between.
A great example is a small office's internal inventory management tool. An employee’s computer (the client) runs an application that sends queries directly to the company's database server to check stock levels or add a new product. It’s clean, simple, and fast.
This direct-line approach is easy to build and maintain, making it perfect for smaller, internal applications where simplicity is key. The downside? It can create security risks by giving the client a direct connection to the database. It can also get bogged down if too many users try to connect at once.
The Versatile 3-Tier Architecture
To get around the limitations of the 2-tier model, nearly every modern web application uses a 3-tier architecture. This design introduces a crucial middle layer—often called the application tier or logic tier—that sits between the client and the database.
Here's how the three layers break down:
- Presentation Tier (The Client): This is the user interface—what you see and click on in your browser or a mobile app. For example, the login page of your online banking portal.
- Application Tier (The Middle Server): This is where the "brains" of the operation live. When you enter your credentials and hit "Log In," your request goes here first. This server handles the business logic—it verifies your password, checks for two-factor authentication, and figures out what data to ask the database for.
- Data Tier (The Database Server): This layer's only job is to store, manage, and retrieve data. It only talks to the application tier, never directly to the client. It’s where your account balance and transaction history are securely stored.
This separation of duties is a game-changer. By isolating the database behind an application layer, systems become far more secure, scalable, and easier to update. Your browser never gets anywhere near the raw data, which is a massive security advantage.
This flow of requests and responses is the engine that powers these connections.
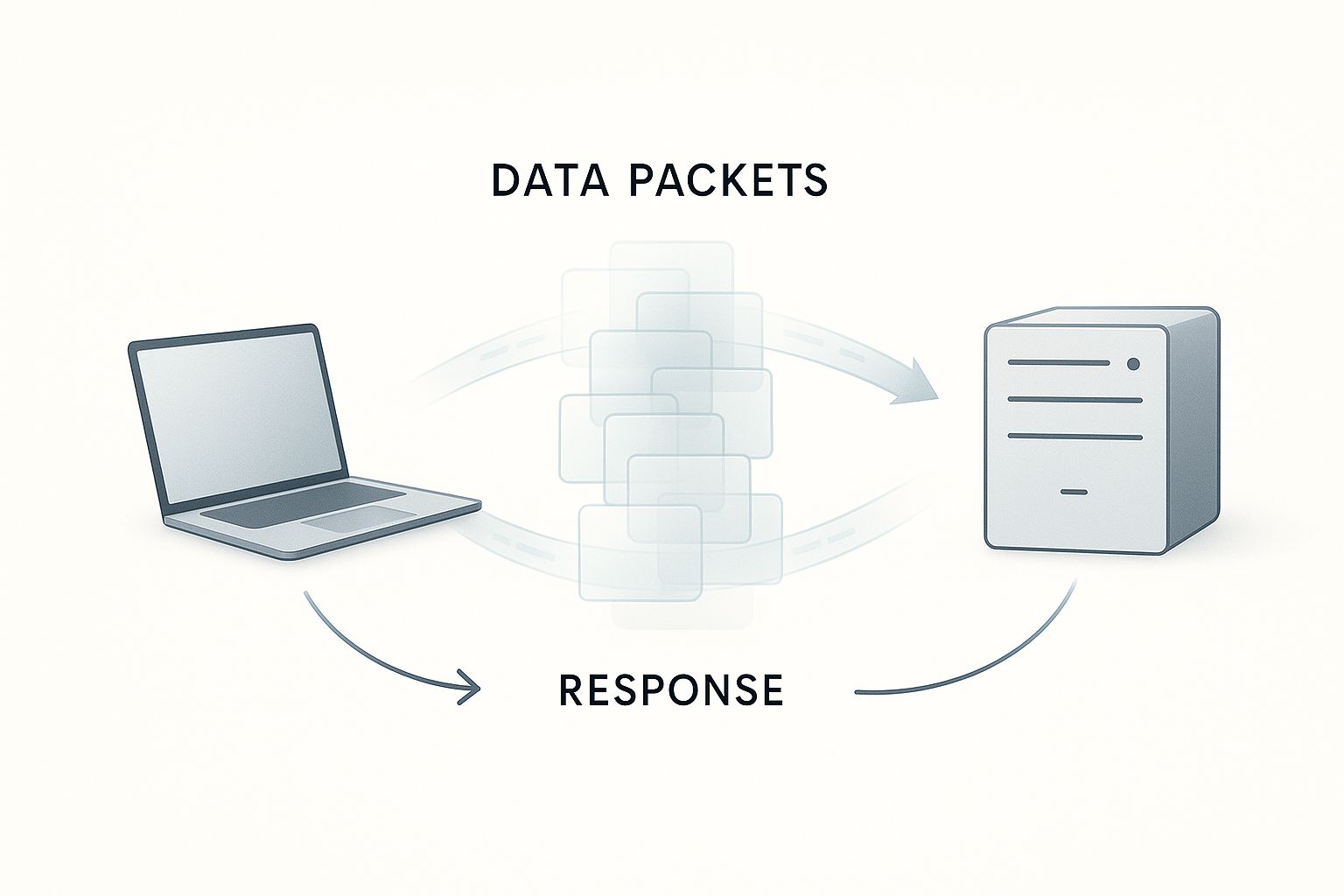
The image above neatly visualizes this back-and-forth communication between a client and a server, which is the heart of any tiered architecture.
The Complex N-Tier Architecture
For massive, enterprise-level systems, even three tiers aren't enough. That's where N-tier architecture enters the picture. The "N" just means "many," signaling that the application is split into multiple, specialized middle layers.
Just think about an e-commerce platform like Amazon. Its backend isn't one giant application server; it's a collection of many specialized services:
- A dedicated server for processing payments.
- Another server for managing user accounts and profiles.
- A separate service just for generating product recommendations.
- And another for handling all the shipping and logistics.
This approach offers the ultimate flexibility and scalability for incredibly complex operations.
To see how these tiers stack up, here’s a quick comparison:
Comparing Architectural Tiers
| Tier Type | Structure | Primary Advantage | Common Example |
|---|---|---|---|
| 2-Tier | Client communicates directly with the database. | Simplicity and speed for small-scale applications. | A desktop inventory management tool. |
| 3-Tier | Client -> Application Server -> Database Server. | Enhanced security, scalability, and maintainability. | Most web applications (e.g., online banking). |
| N-Tier | Client -> Multiple specialized servers -> Database(s). | Maximum scalability and flexibility for complex systems. | Large-scale e-commerce or streaming platforms. |
Ultimately, choosing the right tier depends entirely on the job at hand. A simple task calls for a simple solution, while a complex global service requires a much more sophisticated, layered approach. This high level of separation lets different teams work on parts of the application independently and allows the business to scale up specific functions—like payment processing—without touching anything else.
For those building complex systems, selecting the right specialized components is essential. You can explore a list of different MCP database servers to get a better sense of how these powerful, dedicated pieces fit into a larger N-tier puzzle.
The Evolution of Server Hardware
The raw power of the client-server model is directly tied to the machines it runs on. The architecture's potential has grown with every leap in hardware capability, taking us from a single computer on a desk to the massive, globe-spanning data centers we rely on today.
This journey wasn't just about making computers faster. It was about making them smaller, more efficient, and easier to manage at a colossal scale.
From Desktops to Data Centers
Early on, servers were often just powerful desktop computers. But as the internet’s demands exploded, simply stacking more and more individual machines became wildly impractical. This problem sparked a series of key hardware innovations, all focused on density and efficiency.
The goal was simple: pack as much computing power as possible into a limited physical space while keeping heat and energy consumption under control.
A major step forward came in 1993 when Compaq introduced the ProLiant series of rack-mounted servers. This brilliant design allowed companies to neatly stack multiple servers in a single cabinet, saving precious floor space. Then, in 2001, the blade server arrived, stripping away redundant components and power supplies for an even more compact and efficient setup.
These advancements culminated in breakthroughs like HP's Moonshot server in 2013, which used low-energy microprocessors perfect for the unique demands of cloud data centers. You can dive into the history of server hardware on techtarget.com to explore more of these innovations.
From Physical Machines to Virtual Worlds
This relentless drive for hardware efficiency set the stage for the next big shift: virtualization and cloud computing.
Instead of dedicating one physical server to a single task, virtualization technology allowed one powerful machine to be logically split into multiple virtual servers. Each virtual server acts like its own independent computer, but they all share the resources of the same underlying physical hardware.
This concept of virtualization was fundamental. It broke the rigid link between software and a specific piece of hardware, paving the way for the incredible flexibility and scale of modern cloud platforms.
Cloud providers like Amazon Web Services (AWS) and Google Cloud took this idea and ran with it. They built enormous data centers filled with these highly optimized servers and offered access to this computing power as a utility.
Now, anyone can spin up a virtual server in minutes without ever touching a physical machine. This physical evolution—from desktop towers to racks, blades, and finally to virtualized cloud infrastructure—is what makes today's internet possible, providing the foundation for everything the client-server architecture delivers.
How Client-Server Architecture Powers Modern Business
The client-server model isn't some dusty concept from an old textbook; it's the very engine running today’s most demanding business operations. The simple idea of separating a request from a response has scaled up to power everything from global e-commerce giants to the cloud itself.
This architecture has grown far beyond just serving up websites. Today, it’s the backbone for critical business systems that need to be secure, fast, and cost-effective. The model’s real genius lies in its flexibility—its ability to evolve and meet new challenges head-on.
The Rise of Hybrid and Multi-Cloud Environments
One of the biggest shifts we've seen is the move to hybrid and multi-cloud strategies. Businesses are no longer forced into an all-or-nothing decision between on-premise servers and the public cloud. Now, they can mix and match.
Think about a financial services firm. They might keep their most sensitive customer data locked down on private, on-premise servers for total control and security. But they can also push anonymized data to powerful public cloud servers for heavy-duty analytics, tapping into massive computing power without risking sensitive information.
This blended approach is a natural evolution of the client-server idea. You have different servers, each specialized for a certain job, all working in concert to provide a single, seamless service. As we've moved through the mid-2020s, hybrid cloud has completely changed how client-server logic is built and deployed. Businesses now use modular servers in regional data centers to handle processing that needs to be fast and close to the user. This distributed, flexible model is what allows companies to operate globally with great performance and reliability, proving just how foundational the architecture remains. You can find more details on this shift in enterprise IT on em360tech.com.
The modern approach isn't about replacing the client-server model but rather distributing it more intelligently across different environments to get the best of all worlds.
What this really shows is that the core principle of client-server—centralized resources serving distributed clients—is as important as ever. By adapting to new tools like containerization, microservices, and distributed computing, this time-tested model continues to be the workhorse driving global business forward.
Frequently Asked Questions

Still have a few questions about how client-server architecture fits into the real world? Let's clear up some of the most common ones.
Is Client-Server Architecture Outdated?
Not even close. While you might hear about newer models like peer-to-peer, the client-server relationship is still the bedrock of the internet. It hasn't been replaced; it has just evolved.
Think about cloud computing, APIs, and microservices—they are all modern interpretations of the same core idea. For example, when you use a weather app, your phone (the client) calls an API on a server to get the latest forecast. That's a classic client-server interaction, just using modern technology. This adaptability is exactly why it remains so relevant.
What Is the Biggest Advantage of This Model?
If you have to pick just one, it’s centralization. Having a single, authoritative server manage all the data and do the heavy lifting is a massive advantage.
This approach gives you better security, much simpler maintenance, and consistency you can count on. When it's time to update something, you do it once on the server, and every single client benefits immediately. For instance, when your banking app gets a security patch, the bank updates its server. You’re instantly protected, often without even needing to download an app update.
How Does This Compare to Peer-to-Peer (P2P)?
The difference is night and day. In a P2P network, every computer is both a client and a server, sharing files and resources directly with each other. There’s no central hub—think of file-sharing services like BitTorrent, where users download pieces of a file directly from each other's computers instead of a single central server.
The real distinction comes down to control. Client-server gives you centralized authority and security, while P2P offers decentralized resilience at the cost of being harder to manage and secure.
For most businesses that need reliability and control over their data, this difference makes the client-server model the obvious choice.
At FindMCPServers, we’re harnessing the power of this proven architecture to connect AI models with the specialized tools they need to perform. Explore our platform to see how dedicated MCP servers can make a real difference in your AI projects.
Ready to learn more? Check us out at https://www.findmcpservers.com.